 info@meradia.com
info@meradia.com


PRÉFACE
Jose Michaelraj, CIPM, CAIA, est Directeur Principal chez Meradia, spécialisé dans l’optimisation des opérations de performance et des technologies pour les gestionnaires d’actifs, les propriétaires d’actifs et les dépositaires. Fort d’une expertise approfondie en gestion moderne des données, Jose a réorganisé les processus de performance, évalué les plateformes d’attribution et développé un outil de validation basé sur la reconnaissance de schémas. Il écrit régulièrement sur le lien entre les besoins métier et les techniques innovantes, et a publié dans le Journal of Performance Measurement ainsi que sur les blogs de la CAIA. Son livre, « Investment Performance Systems – Aligning Data, Math & Workflows », a été publié le 18 février 2025.
Kayalvizhi T. est une future architecte en apprentissage automatique et lauréate du programme IWE League de Goldman Sachs. Elle est le cerveau technique derrière DQ4.6, qu’elle a entièrement conçu et développé. Elle a écrit sur des techniques d’optimisation telles que la descente de gradient, et sur des algorithmes d’apprentissage automatique tels que les arbres de décision. En s’appuyant sur des techniques de science des données et des algorithmes de fouille de données, elle a développé une application pour augmenter les taux de correspondance et révéler des schémas d’exception. Développeuse full-stack maîtrisant Python, elle aime combiner les techniques d’IA avec des solutions centrées sur l’utilisateur.
RÉSUMÉ
Les vérifications de qualité des données sont essentielles pour les opérations de performance d’investissement. Elles valident la précision des rendements et garantissent l’exhaustivité. Les équipes en charge de la performance doivent souvent décider de valider ou non la précision des rendements calculés. Leur expertise et la découverte spontanée de schémas dans les données guident ces décisions.
Peut-on découvrir les heuristiques utilisées par les utilisateurs pour vérifier la qualité des données de performance ?
Doit-on se limiter à des algorithmes préconçus pour détecter des schémas ?
Et si c’était la fonction métier qui devait guider le machine learning, plutôt que l’inverse ?
Peut-on envisager un modèle gagnant-gagnant où utilisateurs et algorithmes collaborent pour accroître la productivité ?
Cet article exploratoire utilise des techniques d’apprentissage automatique pour apporter des éclairages sur ces questions. En étendant les algorithmes disponibles et en intégrant des thématiques propres aux données financières, nous développons un modèle original visant à dévoiler les heuristiques employées dans les vérifications de qualité de la performance.
Règles de Qualité des Données
Il est difficile de maintenir des règles de surveillance de la performance en temps réel.
Des données précises sont essentielles pour calculer correctement les rendements. Des données incorrectes, retardées ou incomplètes peuvent engendrer des rendements erronés. Sans contrôles de qualité, ces rendements erronés pourraient être transmis aux équipes d’investissement, aux clients, et à d’autres parties prenantes, suscitant des inquiétudes.
Il existe deux types de vérifications de qualité :
-
Contrôles de préparation à la performance : ils évaluent la qualité des données en amont du calcul de performance, évitant des traitements inutiles.
-
Contrôles de surveillance de la performance : dernière ligne de défense avant la diffusion des rendements, ils renforcent la confiance dans les résultats communiqués.
Cet article se concentre sur l’analyse des heuristiques appliquées lors des contrôles de surveillance effectués par les équipes opérationnelles. Certaines vérifications sont immuables, comme vérifier si un rendement est nul. D’autres, comme un rendement quotidien supérieur à 5 %, varient selon les conditions de marché ou les classes d’actifs¹.
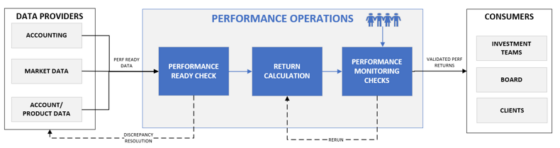
FIGURE 1: Processus Simplifié des Opérations de Performance
Le personnel de performance s’appuie sur de multiples sources d’information – actualités, prix alternatifs, actions d’entreprises, etc. – pour juger de la validité ou non d’un rendement. Il peut ainsi rejeter une confirmation système ou valider une anomalie détectée, en se basant sur son expertise et les informations récentes.
Ce processus est rarement arbitraire : il suit un cadre mental, où les données jouent un rôle central.
Peut-on identifier ces heuristiques grâce à l’apprentissage automatique ?
Modèles d’Apprentissage Automatique & Cadre de Règles Décisionnelles
La modélisation prédictive à base de règles permet une meilleure explicabilité.
Alors que l’IA générative suscite beaucoup d’intérêt, les techniques classiques de machine learning restent puissantes pour les opérations d’investissement. Il est crucial d’appliquer la bonne technique au bon problème.
Les vérifications de qualité relèvent de l’apprentissage supervisé, avec des données étiquetées indiquant si le rendement est « Validé » (Pass) ou « Rejeté » (Fail).
-
Pass : rendement conforme, prêt à être communiqué.
-
Fail : rendement problématique nécessitant investigation.
L’objectif est de déduire les règles à partir des schémas observés. Une fois identifiées, ces règles peuvent prédire les cas futurs. Le cadre utilisé ici repose sur les règles décisionnelles, faciles à interpréter.
DONNÉES D’ENTRAÎNEMENT
Créer un jeu de données déséquilibré : les “Fails” sont plus précieux que les “Pass”.
Notre jeu de données contient 811 enregistrements décrivant un portefeuille à une date donnée.
-
a. Séries temporelles : Données quotidiennes simulées sur 3 mois pour 9 portefeuilles.
-
b. Définition des variables : Données comptables, de performance brute et nette, ainsi que des variables dérivées comme les flux/valeur de marché ou le différentiel portefeuille-benchmark.
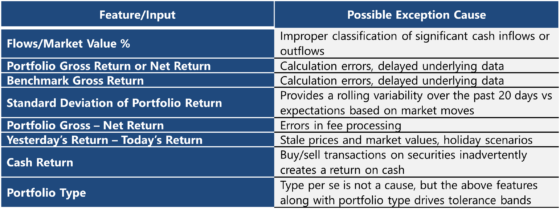
TABLE 1: Feature Definition
-
c. Classes : Chaque enregistrement est étiqueté “Pass” ou “Fail”.
-
d. Distribution : Environ 771 Pass et 40 Fail, ce qui reflète la réalité : peu d’exceptions.
Modèle DQ4.6
Utiliser des thèmes spécifiques liés aux données d’investissement pour améliorer les contrôles de qualité.
Notre modèle DQ4.6 est une extension de l’algorithme C4.5 de Quinlan³.
Améliorations apportées :
-
Conversion des variables continues : en catégories nominales via des seuils (ex. : rendement > 1%, > 2%, etc.).
-
Sélection de variables : exploration de toutes les règles possibles et usage du Gain Ratio⁴ pour traiter les données déséquilibrées.
VALIDATION DU MODÈLE
Les règles générées suivent une structure simple, ex. :
-
|Variable| > valeur seuil
-
|Variable 1 – Variable 2| > seuil
-
|Variable 1 / Variable 2| > seuil
-
Variable = NULL
-
Variable = valeur spécifique (ex. EQ, FI)
Les résultats pour la classe Fail sont comparés aux règles connues, et le modèle propose également de nouvelles règles pertinentes. Les utilisateurs peuvent les adopter pour améliorer les contrôles futurs.
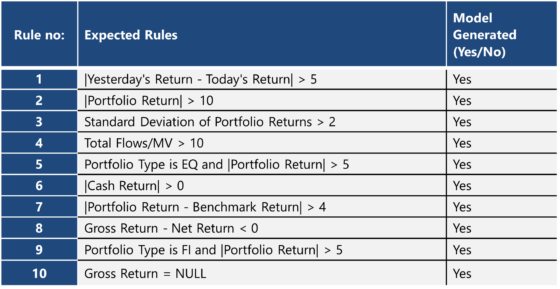
TABLE 2: Expected Rules vs. Model Output
CONCLUSION
En simulant des données, en appliquant des règles de qualité et en adaptant des algorithmes existants, nous avons codifié les heuristiques utilisées lors des vérifications de performance. Le cas de la performance illustre que le modèle fonctionne, mais DQ4.6⁵ peut être appliqué à d’autres services dans la gestion d’actifs.
L’apprentissage automatique peut transformer les opérations d’investissement. Il permet une transition du modèle “investigation-correction” vers “validation-confirmation”, réduisant les efforts d’analyse tout en améliorant la tolérance aux anomalies.
Des modèles auto-apprenants et auto-correcteurs peuvent émerger. Comme le dit Bill Gates⁶, « La technologie progresse lorsqu’elle devient invisible et s’intègre à la vie quotidienne. »
Nous espérons que cet article suscitera réflexions et débats.
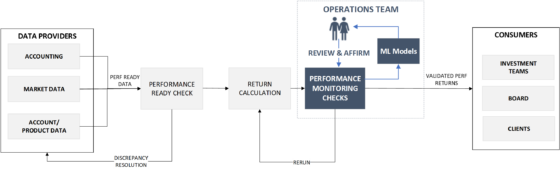
FIGURE 2: Self-correcting, auto-learning Operational Models
The authors would like to thank their mentor Vijay Chandrasekhar, an Investment Performance data expert with machine learning interests who explored this idea with us, perhaps more deeply at times.
RÉFÉRENCES
¹ Journal of Performance Measurement, Fall 2023 – Rapport du Data Quality Working Group
² D’autres techniques de machine learning : détection d’anomalies, analyse de clusters, analyse d’associations
³ C4.5 – Programs for Machine Learning, J. Ross Quinlan
⁴ Exemples de critères pour la qualité des divisions d’un arbre décisionnel : Gain Ratio, Information Gain, Indice de Gini
⁵ Le code de DQ4.6 est écrit en Python
⁶ Citation attribuée à Bill Gates